
Statistical Analysis:
Developing and Testing Hypotheses
See also: Significance and Confidence Intervals
Statistical hypothesis testing is sometimes known as confirmatory data analysis. It is a way of drawing inferences from data. In the process, you develop a hypothesis or theory about what you might see in your research. You then test that hypothesis against the data that you collect.
Hypothesis testing is generally used when you want to compare two groups, or compare a group against an idealised position.
Before You Start: Developing A Research Hypothesis
Before you can do any kind of research in social science fields such as management, you need a research question or hypothesis. Research is generally designed to either answer a research question or consider a research hypothesis. These two are closely linked, and generally one or the other is used, rather than both.
A research question is the question that your research sets out to answer. For example:
Do men and women like ice cream equally?
Do men and women like the same flavours of ice cream?
What are the main problems in the market for ice cream?
How can the market for ice cream be segmented and targeted?
Research hypotheses are statements of what you believe you will find in your research.
These are then tested statistically during the research to see if your belief is correct. Examples include:
Men and women like ice cream to different extents.
Men and women like different flavours of ice cream.
Men are more likely than women to like mint ice cream.
Women are more likely than men to like chocolate ice cream.
Both men and women prefer strawberry to vanilla ice cream.
Relationships vs Differences
Research hypotheses can be expressed in terms of differences between groups, or relationships between variables. However, these are two sides of the same coin: almost any hypothesis could be set out in either way.
For example:
There is a relationship between gender and liking ice cream OR
Men are more likely to like ice cream than women.
Testing Research Hypotheses
The purpose of statistical hypothesis testing is to use a sample to draw inferences about a population.
Testing research hypotheses requires a number of steps:
Step 1. Define your research hypothesis
The first step in any hypothesis testing is to identify your hypothesis, which you will then go on to test. How you define your hypothesis may affect the type of statistical testing that you do, so it is important to be clear about it. In particular, consider whether you are going to hypothesise simply that there is a relationship or speculate about the direction of the relationship.
Using the examples above:
There is a relationship between gender and liking ice cream is a non-directional hypothesis. You have simply specified that there is a relationship, not whether men or women like ice cream more.
However, men are more likely to like ice cream than women is directional: you have specified which gender is more likely to like ice cream.
Generally, it is better not to specify direction unless you are moderately sure about it.
Step 2. Define the null hypothesis
The null hypothesis is basically a statement of what you are hoping to disprove: the opposite of your ‘guess’ about the relationship. For example, in the hypotheses above, the null hypothesis would be:
Men and women like ice cream equally, or
There is no relationship between gender and ice cream.
This also defines your ‘alternative hypothesis’ which is your ‘test hypothesis’ (men like ice cream more than women). Your null hypothesis is generally that there is no difference, because this is the simplest position.
The purpose of hypothesis testing is to disprove the null hypothesis. If you cannot disprove the null hypothesis, you have to assume it is correct.
Step 3. Develop a summary measure that describes your variable of interest for each group you wish to compare
Our page on Simple Statistical Analysis describes several summary measures, including two of the most common, mean and median.
The next step in your hypothesis testing is to develop a summary measure for each of your groups. For example, to test the gender differences in liking for ice cream, you might ask people how much they liked ice cream on a scale of 1 to 5. Alternatively, you might have data about the number of times that ice creams are consumed each week in the summer months.
You then need to produce a summary measure for each group, usually mean and standard deviation. These may be similar for each group, or quite different.
Step 4. Choose a reference distribution and calculate a test statistic
To decide whether there is a genuine difference between the two groups, you have to use a reference distribution against which to measure the values from the two groups.
The most common source of reference distributions is a standard distribution such as the normal distribution or t- distribution. These two are the same, except that the standard deviation of the t-distribution is estimated from the sample, and that of the normal distribution is known. There is more about this in our page on Statistical Distributions.
You then compare the summary data from the two groups by using them to calculate a test statistic. There is a standard formula for every test statistic and reference distribution. The test and reference distribution depend on your data and the purpose of your testing (see below).
What Test?
The test that you use to compare your groups will depend on how many groups you have, the type of data that you have collected, and how reliable your data are. In general, you would use different tests for comparing two groups than you would for comparing three or more.
Our page Surveys and Survey Design explains that there are two types of answer scale, continuous and categorical. Age, for example, is a continuous scale, although it can also be grouped into categories. You may also find it helpful to read our page on Types of Data.
Gender is a category scale.
For a continuous scale, you can use the mean values of the two groups that you are comparing.
For a category scale, you need to use the median values.
| Purpose | Data Scale | Average | Test | Test Statistic | Reference Distribution |
| Compare two groups | Continuous | Mean | t-test | t | t |
| Category | Median | Mann-Whitney U test | U statistic | All combination of ranks | |
| Compare three or more groups | Continuous | Mean | Analysis of Variance (ANOVA) | F-ratio | F |
| Category | Median | Kruskal-Wallis Test | W statistic | All combination of ranks |
Source: Easterby-Smith, Thorpe and Jackson, Management Research 4th Edition
One- or Two-Tailed Test
The other thing that you have to decide is whether you use what is known as a ‘one-tailed’ or ‘two-tailed’ test.
This allows you to compare differences between groups in either one or both directions.
In practice, this boils down to whether your research hypothesis is expressed as ‘x is likely to be more than y’, or ‘x is likely to be different from y’. If you are confident of the direction of the distance (that is, you are sure that the only options are that ‘x is likely to be more than y’ or ‘x and y are the same’), then your test will be one-tailed. If not, it will be two-tailed.
If there is any doubt, it is better to use a two-tailed test.
You should only use a one-tailed test when you are certain about the direction of the difference, and it doesn’t matter if you are wrong.
The graph under Step 5 shows a two-tailed test.
Warning!
If you are not very confident about the quality of the data collected, for example because the inputting was done quickly and cheaply, or because the data have not been checked, then you may prefer to use the median even if the data are continuous to avoid any problems with outliers. This makes the tests more robust, and the results more reliable.
Our page on correlations suggests that you may also want to plot a scattergraph before undertaking any further analysis. This will also help you to identify any outliers or potential problems with the data.
Calculating the Test Statistic
For each type of test, there is a standard formula for the test statistic. For example, for the t-test, it is:
(M1-M2)/SE(diff)
M1 is the mean of the first group
M2 is the mean of the second group
SE(diff) is the standard error of the difference, which is calculated from the standard deviation and the sample size of each group.
The formula for calculating the standard error of the difference between means is:
$$\sqrt{(sd^2/n_a)+(sd^2/n_b)}$$Where
- sd2 = the square of the standard deviation of the source population (i.e., the variance);
- na = the size of sample A; and
- nb = the size of sample B.
Step 5. Identify Acceptance and Rejection Regions
The final part of the test is to see if your test statistic is significant—in other words, whether you are going to accept or reject your null hypothesis. You need to consider first what level of significance is required. This tells you the probability that you have achieved your result by chance.
Significance (or p-value) is usually required to be either 5% or 1%, meaning that you are 95% or 99% confident that your result was not achieved by chance.
NOTE: the significance level is sometimes expressed as p < 0.05 or p < 0.01.
For more about significance, you may like to read our page on Significance and Confidence Intervals.
The graph below shows a reference distribution (this one could be either the normal or the t-distribution) with the acceptance and rejection regions marked. It also shows the critical values. µ is the mean. For more about this, you may like to read our page on Statistical Distributions.
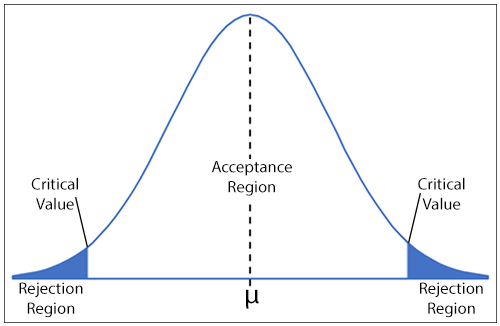
The critical values are identified from published statistical tables for your reference distribution, which are available for different levels of significance.
If your test statistic falls within either of the two rejection regions (that is, it is greater than the higher critical value, or less than the lower one), you will reject the null hypothesis. You can therefore accept your alternative hypothesis.
Step 6. Draw Conclusions and Inferences
The final step is to draw conclusions.
If your test statistic fell within the rejection region, and you have rejected the null hypothesis, you can therefore conclude that there is a gender difference in liking for ice cream, using the example above.
Types of Error
There are four possible outcomes from statistical testing (see table):
The groups are different, and you conclude that they are different (correct result)
The groups are different, but you conclude that they are not (Type II error)
The groups are the same, but you conclude that they are different (Type I error)
The groups are the same, and you conclude that they are the same (correct result).
| Actual position | ||
| Conclusion from data | Groups are the same | Groups are different |
| Data shows no difference between groups | Correct conclusion will be drawn | Type II error |
| Data shows a difference between groups | Type I error | Correct conclusion will be drawn |
Source: Easterby-Smith, Thorpe and Jackson, Management Research 4th Edition
Type I errors are generally considered more important than Type II, because they have the potential to change the status quo.
For example, if you wrongly conclude that a new medical treatment is effective, doctors are likely to move to providing that treatment. Patients may receive the treatment instead of an alternative that could have fewer side effects, and pharmaceutical companies may stop looking for an alternative treatment.

Further Reading from Skills You Need
Data Handling and Algebra
Part of The Skills You Need Guide to Numeracy
This eBook covers the basics of data handling, data visualisation, basic statistical analysis and algebra. The book contains plenty of worked examples to improve understanding as well as real-world examples to show you how these concepts are useful.
Whether you want to brush up on your basics, or help your children with their learning, this is the book for you.
A Word of Advice
There are statistical software packages available that will carry out all these tests for you. However, if you have never studied statistics, and you’re not very confident about what you’re doing, you are probably best off discussing it with a statistician or consulting a detailed statistical textbook.
Poorly executed statistical analysis can invalidate very good research. It is much better to find someone to help you. However, this page will help you to understand your friendly statistician!